7/24 Uptime Monitör Takibi
 SEOBAZ
SEOBAZ

7/24 uptime monitör takibi, web sunucusunun erişilebilirlik durumunu kesintisiz izleyen ve kesinti anında anlık uyarı göndererek müdahale süresini minimize eden otomatik denetim sistemidir. 2026 itibarıyla arama motoru tarayıcıları ardışık 5xx yanıtı alan sitelerin tarama sıklığını otomatik olarak düşürmekte ve dizin kapsamını daraltmaktadır. Seobaz teknik SEO çerçevesinde uptime izleme, çoklu konum doğrulaması, içerik tabanlı kontrol, SSL sertifika izleme ve webhook tabanlı otomatik kurtarma gerektiren kritik bir altyapı takibi disiplinidir.
🧠 Bu Rehberi 5 Farklı AI ile Test Et
Her modelin GEO karakterine göre özel prompt hazırlandı. Tıkla, kopyalansın ve ilgili AI açılsın.
Uptime monitör, bir web sitesinin erişilebilirlik durumunu kesintisiz olarak izleyen ve kesinti anında anlık uyarı gönderen otomatik denetim sistemidir. 2026 itibarıyla arama motoru tarayıcıları ardışık 5xx yanıtı alan sitelerin tarama sıklığını otomatik olarak düşürmekte ve uzun süreli kesintilerde dizin kapsamını daraltmaktadır. Bu mekanizma, sunucu erişilebilirliğini yalnızca kullanıcı deneyimi değil doğrudan organik görünürlük metrikleri üzerinde etkili bir teknik SEO parametresine dönüştürdü.
Uptime Kavramının Teknik Tanımı ve Ölçüm Birimi
Uptime, bir web sunucusunun HTTP isteklerine başarılı yanıt verdiği sürenin toplam süreye oranını ifade eder. Yüzde olarak ölçülür ve endüstri standardı "dokuzlar" terminolojisiyle ifade edilir. Yüzde 99.9 uptime (üç dokuz) yılda maksimum 8 saat 45 dakika kesinti anlamına gelir. Yüzde 99.99 (dört dokuz) ise yılda yalnızca 52 dakika kesintiye karşılık gelir.
Bu fark küçük görünse de SEO etkisi açısından kritiktir. Googlebot'un tarama penceresi ile kesinti zamanlaması çakıştığında, tarayıcı 5xx yanıtı alır ve sayfayı "erişilemez" olarak işaretler. Ardışık taramalarda aynı yanıt tekrarlanırsa, sayfa dizinden geçici olarak düşürülebilir. Dolayısıyla uptime oranı yalnızca kullanıcı kaybını değil, dizin kapsamı kaybını da doğrudan etkiler.
Kesinti Türleri ve HTTP Durum Kodları
Sunucu kesintileri farklı HTTP durum kodlarıyla kendini gösterir. Her kod farklı bir sorun kaynağına işaret eder ve arama motoru tarafından farklı şekilde değerlendirilir. 500 (Internal Server Error) sunucu tarafında genel bir hatayı, 502 (Bad Gateway) ters proxy veya yük dengeleyicinin arka uç sunucuya ulaşamadığını, 503 (Service Unavailable) sunucunun geçici olarak hizmet veremediğini ve 504 (Gateway Timeout) arka uç sunucunun zaman aşımına uğradığını bildirir.
Arama motoru tarayıcısı 503 yanıtını "geçici bakım" olarak yorumlar ve sayfayı dizinden düşürmez. Retry-After header'ı eklendiğinde tarayıcı belirtilen süre sonra yeniden dener. Aksine 500 yanıtı kalıcı bir sorun sinyalidir ve tekrarlanması durumunda dizin kaybına yol açar. Planlı bakımlarda 503 durum kodu ve Retry-After header'ı kullanmak dizin korumasının temel güvencesidir.
Uptime Monitör Çalışma Prensibi
Uptime monitör sistemi, belirlenen aralıklarla hedef URL'ye HTTP isteği gönderir ve yanıtı değerlendirir. Başarılı yanıt (2xx) alındığında site erişilebilir kabul edilir. Başarısız yanıt (4xx, 5xx) veya zaman aşımı durumunda kesinti kaydedilir ve uyarı mekanizması tetiklenir.
Kontrol aralığı, tespit hızını belirler. 1 dakikalık kontrol aralığı, kesintinin en geç 1 dakika içinde tespit edilmesini sağlar. 5 dakikalık aralık ise tespit süresini 5 dakikaya uzatır. SEO açısından kritik sitelerde 1 dakikalık kontrol aralığı tercih edilmelidir çünkü Googlebot'un tarama penceresiyle çakışma riski minimize edilir. Uzun kontrol aralıkları, kısa süreli kesintilerin tamamen gözden kaçmasına neden olur.
Çoklu Konum Tabanlı İzleme ve False Positive Önleme
Tek bir izleme noktasından yapılan kontrol, ağ sorunlarını sunucu sorunlarından ayırt edemez. İzleme sunucusu ile hedef sunucu arasındaki ağ kesintisi, sitenin erişilemez olarak raporlanmasına yol açar. Gerçekte site çalışıyordur ancak izleme noktasından erişilemiyordur.
Çoklu konum izleme bu sorunu çözer. Farklı coğrafi konumlardaki (ABD, Avrupa, Asya) izleme noktaları aynı anda kontrol yapar. Kesinti, birden fazla konumdan doğrulandığında gerçek kesinti olarak kaydedilir. Yalnızca tek konumdan tespit edilen erişim sorunu, bölgesel ağ problemi olarak sınıflandırılır ve false alarm olarak filtrelenir. Bu mekanizma, uyarı güvenilirliğini artırır ve gereksiz alarm yorgunluğunu önler.
HTTP, HTTPS ve TCP Katmanlarında İzleme
Uptime monitör yalnızca HTTP katmanında çalışmaz. TCP port kontrolü, sunucunun belirtilen port üzerinden bağlantı kabul edip etmediğini doğrular. HTTP(S) kontrolü ise uygulamanın doğru yanıt verip vermediğini test eder. Her iki katmanın birlikte izlenmesi, sorunun kaynağını hızlı belirlemeyi sağlar.
TCP kontrolünde port 443 (HTTPS) ve port 80 (HTTP) izlenir. Bu kontrol, web sunucusu yazılımının (Nginx, Apache) çalışıp çalışmadığını doğrular. HTTP kontrolünde ise belirli bir URL'ye istek gönderilir ve yanıt kodu, yanıt süresi ve yanıt içeriği değerlendirilir. Yanıt kodunun 200 olması tek başına yeterli değildir. Yanıt içeriğinde belirli bir anahtar kelimenin (örneğin site adı) bulunup bulunmadığı kontrol edilmelidir. Çünkü bazı kesinti senaryolarında CDN veya proxy katmanı 200 OK dönerken içerik hata mesajı barındırır.
Yanıt Süresi İzleme ve Performans Eşikleri
Uptime monitör yalnızca erişilebilirliği değil, yanıt süresini de izlemelidir. Sunucu yanıt süresi (Time to First Byte, TTFB) arttığında kullanıcı deneyimi ve tarama verimliliği bozulur. 200 milisaniye altı TTFB ideal, 500 milisaniye üzeri sorunlu ve 1000 milisaniye üzeri kritik olarak sınıflandırılır.
Yanıt süresi trendi izlendiğinde yavaşlama kalıpları tespit edilir. Her gün saat 10:00 ile 12:00 arasında yanıt süresinin 800 milisaniyeye çıkması, o saatlerdeki trafik yoğunluğunun sunucu kapasitesini zorladığını gösterir. Bu veri, kapasite planlaması ve CDN yapılandırması için doğrudan girdi sağlar. Anlık yavaşlamalar alarm tetiklemese de trend bazlı yavaşlama kalıcı sorunun habercisidir.
SSL Sertifika Süresi İzleme
SSL sertifikasının süresinin dolması, tarayıcıda güvenlik uyarısı tetikler ve organik trafiği anında çökertir. Uptime monitör sistemleri SSL sertifika bitiş tarihini izleyebilir ve süre dolmadan önce uyarı gönderebilir.
Sertifika izleme için 30 gün, 14 gün ve 7 gün kalan eşiklerinde kademeli uyarı yapılandırılmalıdır. İlk uyarı yenileme sürecini başlatır, ikinci uyarı hatırlatma işlevi görür, üçüncü uyarı ise acil müdahale gerektirir. Otomatik sertifika yenileme (Let's Encrypt certbot) kullanılsa bile izleme devre dışı bırakılmamalıdır çünkü otomatik yenileme DNS değişiklikleri veya sunucu yapılandırma hataları nedeniyle başarısız olabilir.
# SSL sertifika bitiş tarihini kontrol eden basit betik
DOMAIN="site.com"
EXPIRY=$(echo | openssl s_client -connect $DOMAIN:443 2>/dev/null | \
openssl x509 -noout -enddate | cut -d= -f2)
EXPIRY_EPOCH=$(date -d "$EXPIRY" +%s)
NOW_EPOCH=$(date +%s)
DAYS_LEFT=$(( (EXPIRY_EPOCH - NOW_EPOCH) / 86400 ))
echo "Sertifika bitis: $EXPIRY ($DAYS_LEFT gun kaldi)"
if [ "$DAYS_LEFT" -lt 14 ]; then
echo "UYARI: SSL sertifikasi $DAYS_LEFT gun icinde dolacak!"
fi
Uyarı Kanalları ve Eskalasyon Yapılandırması
Kesinti tespit edildiğinde uyarının doğru kanala ve doğru kişiye ulaşması müdahale süresini belirler. E-posta, SMS, Slack, Telegram ve webhook olmak üzere birden fazla uyarı kanalı yapılandırılmalıdır.
Eskalasyon yapısı şöyle kurgulanır: ilk uyarı (0. dakika) Slack kanalına ve sorumlu geliştiricinin e-postasına gönderilir. Kesinti 5 dakikayı aştığında SMS uyarısı tetiklenir. 15 dakikayı aştığında ekip yöneticisine eskalasyon yapılır. 30 dakikayı aştığında üst yönetime bildirim gider. Bu kademeli yapı, kısa süreli kesintilerde gereksiz alarm üretmezken uzun süreli kesintilerde yönetim seviyesinde farkındalık sağlar.
Webhook Entegrasyonu ile Otomatik Müdahale
Uptime monitör sistemleri, kesinti tespit edildiğinde webhook URL'sine HTTP POST isteği göndererek otomatik müdahale süreçlerini tetikleyebilir. Bu entegrasyon, insan müdahalesi olmadan otomatik kurtarma senaryolarını devreye alır.
Webhook ile otomatik sunucu yeniden başlatma örneği:
from flask import Flask, request
import subprocess
app = Flask(__name__)
@app.route('/webhook/downtime', methods=['POST'])
def handle_downtime():
data = request.json
if data.get('status') == 'down':
site = data.get('url', '')
# Nginx yeniden başlat
subprocess.run(['sudo', 'systemctl', 'restart', 'nginx'],
capture_output=True)
# PHP-FPM yeniden başlat
subprocess.run(['sudo', 'systemctl', 'restart', 'php8.2-fpm'],
capture_output=True)
# Sonucu logla
with open('/var/log/auto-recovery.log', 'a') as f:
f.write(f'{site} - otomatik kurtarma tetiklendi\n')
return {'status': 'recovery_triggered'}, 200
return {'status': 'ignored'}, 200
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Bu script, webhook isteği aldığında Nginx ve PHP-FPM servislerini otomatik olarak yeniden başlatır. Basit sunucu sorunlarında (bellek sızıntısı, bağlantı havuzu tükenmesi) bu otomatik müdahale, insan müdahalesine gerek kalmadan siteyi saniyeler içinde kurtarır.
Planlı Bakım Pencerelerinde SEO Koruma Stratejisi
Sunucu güncellemesi, veritabanı bakımı veya altyapı değişikliği sırasında planlı kesinti gerekebilir. Bu kesintilerin arama motoru dizinini etkilememesi için HTTP 503 durum kodu ve Retry-After header'ı kullanılmalıdır.
Nginx'te bakım modu yapılandırması:
# Bakım modu aktif edildiğinde
if (-f /var/www/maintenance.flag) {
return 503;
}
error_page 503 @maintenance;
location @maintenance {
add_header Retry-After 3600 always;
add_header Content-Type "text/html; charset=utf-8" always;
return 503 '<html><body><h1>Bakim devam ediyor</h1><p>Kisa sure icinde geri donecegiz.</p></body></html>';
}
Bakım başlatılırken /var/www/maintenance.flag dosyası oluşturulur, bakım tamamlandığında silinir. Retry-After: 3600 header'ı tarayıcıya "1 saat sonra tekrar dene" mesajı gönderir. Bu yapılandırma, Googlebot'un bakım sırasında sayfaları dizinden düşürmesini engeller. Bakım süresi 24 saati aşmamalıdır, uzun süreli bakımlarda alternatif sunum stratejileri uygulanmalıdır.
Usta Notu: Portföydeki Eksik Halka
Pek çok teknik SEO uzmanının portföyünde eksik olan ama kaybı en yüksek alanlardan biri budur: uptime izleme. Onlarca saat crawl budget optimizasyonu, yapısal veri düzeltmesi ve içerik stratejisi planlaması yapılır. Ancak gece 03:00'te sunucu çöktüğünde ve 4 saat boyunca kimse fark etmediğinde, Googlebot bu sürede onlarca sayfadan 5xx yanıtı alır. Sabah ekip işe geldiğinde Search Console'da tarama hataları çoktan birikmiştir. Sahadaki gözlemlerimize göre, fark edilmeyen 4 saatlik bir kesinti sonrası tarama sıklığının eski seviyesine dönmesi 5 ila 10 gün sürmektedir. Bu sürede yeni yayımlanan içeriklerin dizinlenmesi gecikir ve organik görünürlük kaybı oluşur. Uptime monitör kurulumu 10 dakika sürer, bu 10 dakikalık yatırım potansiyel olarak haftalarca sürecek dizin kurtarma sürecini tamamen ortadan kaldırır.
Statuspage ve Durum Sayfası Yapılandırması
Halka açık bir durum sayfası (status page), kullanıcılara ve paydaşlara sitenin anlık erişilebilirlik durumunu gösterir. Kesinti anında kullanıcıların destek ekibini yoğun şekilde aramasını önler ve iletişim yükünü azaltır.
Durum sayfasında gösterilmesi gereken bileşenler: web sitesi durumu, API durumu, CDN durumu, veritabanı durumu ve e-posta servisi durumu. Her bileşen "Çalışıyor", "Performans sorunu", "Kısmi kesinti" veya "Tam kesinti" olarak raporlanır. Geçmiş kesinti kayıtları ve ortalama uptime oranı da sayfada yer almalıdır. Bu şeffaflık, kullanıcı güvenini artırır ve profesyonel operasyon algısı oluşturur.
DNS İzleme ve Çözümleme Süresi Takibi
Sunucu çalışıyor olsa bile DNS çözümlemesi başarısız olduğunda site erişilemez hale gelir. DNS sunucusu kesintisi, yanlış DNS kaydı veya DNS yayılım gecikmesi bu duruma yol açar. DNS izleme, uptime monitörün tamamlayıcı bileşenidir.
DNS çözümleme süresi ve doğruluğu izlenmelidir. Normal DNS çözümleme süresi 50 milisaniyenin altındadır. 200 milisaniye üzeri değerler DNS altyapısında sorun olduğuna işaret eder. DNS kayıtlarının doğruluğu da kontrol edilmelidir: A kaydının doğru IP'ye işaret ettiği, CNAME kaydının doğru hedefi gösterdiği ve MX kayıtlarının çalışır durumda olduğu düzenli olarak doğrulanmalıdır.
# DNS çözümleme süresi ve doğruluk kontrolü
DOMAIN="site.com"
# Çözümleme süresi
dig +stats $DOMAIN | grep "Query time"
# A kaydı doğrulama
RESOLVED_IP=$(dig +short $DOMAIN)
EXPECTED_IP="185.199.108.153"
if [ "$RESOLVED_IP" != "$EXPECTED_IP" ]; then
echo "UYARI: DNS kaydi beklenenden farkli! Mevcut: $RESOLVED_IP"
fi
Veritabanı ve Uygulama Katmanı İzleme
HTTP katmanında 200 OK dönen bir site, veritabanı bağlantısı koptuğunda hata sayfası gösterebilir. Uptime monitör HTTP yanıt kodunu kontrol eder ve 200 OK alır. Ancak sayfa içeriği "Veritabanı bağlantısı kurulamadı" hata mesajını barındırır. Bu durum, keyword-based content monitoring ile tespit edilir.
İçerik tabanlı izleme, HTTP yanıtının belirli bir anahtar kelimeyi içerip içermediğini kontrol eder. Sayfanın <title> etiketi veya body içeriğinde beklenen bir metin (örneğin site adı veya belirli bir başlık) aranır. Bu metin bulunamazsa site "içerik hatası" olarak işaretlenir. WordPress sitelerinde "Error establishing a database connection" veya "Briefly unavailable for scheduled maintenance" gibi hata metinlerinin tespiti, veritabanı ve bakım sorunlarını HTTP katmanından yakalamayı sağlar.
CDN Katmanında Kesinti Tespiti
CDN kullanılan sitelerde origin sunucu çöktüğünde CDN önbelleği stale içerik sunmaya devam edebilir. Bu durumda uptime monitör kesinti tespit etmez çünkü CDN 200 OK döner. Ancak önbellek süresi dolduğunda CDN de hata döner ve gerçek kesinti ortaya çıkar.
CDN bypass kontrolü, origin sunucunun durumunu doğrudan test eder. Özel bir HTTP header veya query parametresiyle CDN önbelleğini atlayan istek gönderilir:
# CDN bypass ile origin kontrolü
curl -H "Cache-Control: no-cache" \
-H "X-Bypass-Cache: true" \
-o /dev/null -s -w "%{http_code} %{time_total}s\n" \
"https://site.com/?nocache=1"
Bu istek, CDN önbelleğini atlayarak doğrudan origin sunucuya ulaşır. Origin yanıt süresi ve durum kodu ayrı olarak izlenir. CDN ve origin izlemesinin birlikte yapılması, kesinti kaynağını (CDN mi, origin mi) hızla belirlemeyi sağlar.
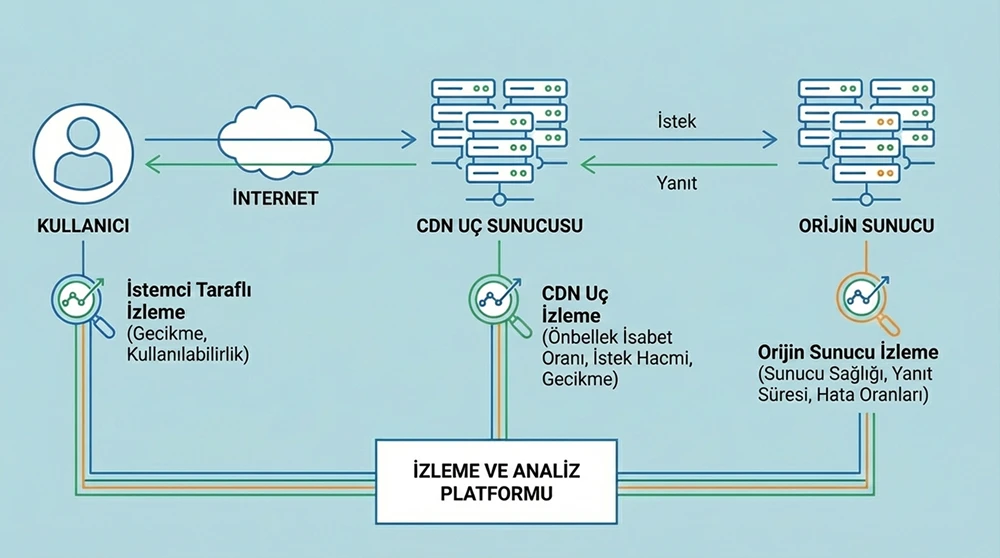
Uptime SLA Hesaplaması ve Raporlama
Uptime oranı, belirli bir dönemdeki toplam erişilebilir sürenin toplam süreye bölünmesiyle hesaplanır. Bu metrik, hosting sağlayıcıları ile yapılan SLA (Service Level Agreement) anlaşmalarının doğrulanması için kullanılır.
Hesaplama formülü:
def uptime_hesapla(toplam_dakika, kesinti_dakika):
uptime = ((toplam_dakika - kesinti_dakika) / toplam_dakika) * 100
return round(uptime, 4)
# Mart 2026 (31 gun = 44640 dakika)
toplam = 31 * 24 * 60 # 44640 dakika
kesinti = 47 # dakika
oran = uptime_hesapla(toplam, kesinti)
print(f'Uptime: %{oran}') # %99.8947
# SLA esik kontrolu
SLA_ESIK = 99.95
if oran < SLA_ESIK:
print(f'SLA ihlali! Hedef: %{SLA_ESIK}, Gerceklesen: %{oran}')
Aylık uptime raporu, kesinti sayısı, toplam kesinti süresi, ortalama müdahale süresi (MTTR) ve en uzun kesinti süresini içermelidir. Bu rapor, hosting altyapısının yeterliliğini değerlendirmek ve kapasite planlaması yapmak için temel veri kaynağıdır.
Kendi Uptime Monitörünü Kurma
Üçüncü parti servislere bağımlılık olmadan kendi uptime monitör sisteminizi kurmak tam kontrol sağlar. Python ile minimal bir izleme betiği:
import requests
import time
import smtplib
from email.mime.text import MIMEText
from datetime import datetime
HEDEFLER = [
{'url': 'https://site.com', 'keyword': 'Seobaz'},
{'url': 'https://site.com/blog', 'keyword': 'Blog'},
{'url': 'https://api.site.com/health', 'keyword': 'ok'},
]
KONTROL_ARALIGI = 60 # saniye
LOG_DOSYASI = '/var/log/uptime-monitor.log'
def kontrol_et(hedef):
try:
r = requests.get(hedef['url'], timeout=15)
sure = r.elapsed.total_seconds()
if r.status_code != 200:
return False, f"HTTP {r.status_code}", sure
if hedef.get('keyword') and hedef['keyword'] not in r.text:
return False, "Icerik hatasi", sure
return True, "OK", sure
except requests.exceptions.Timeout:
return False, "Zaman asimi", 0
except requests.exceptions.ConnectionError:
return False, "Baglanti hatasi", 0
def logla(mesaj):
tarih = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
satir = f'[{tarih}] {mesaj}'
print(satir)
with open(LOG_DOSYASI, 'a') as f:
f.write(satir + '\n')
while True:
for hedef in HEDEFLER:
durum, mesaj, sure = kontrol_et(hedef)
if not durum:
logla(f"KESINTI: {hedef['url']} - {mesaj}")
# Uyari gonder (e-posta, Slack webhook vb.)
else:
logla(f"OK: {hedef['url']} - {sure:.2f}s")
time.sleep(KONTROL_ARALIGI)
Bu betik, belirlenen hedefleri her 60 saniyede kontrol eder, HTTP durum kodunu ve içerik doğruluğunu test eder ve sonuçları loglar. Systemd service olarak yapılandırıldığında sunucu yeniden başlatmalarında otomatik olarak çalışmaya devam eder.
Uptime Verisinin SEO Korelasyon Analizi
Uptime verileri ile Search Console tarama istatistikleri arasındaki korelasyon, kesintilerin SEO etkisini somutlaştırır. Kesinti zamanlaması ile Googlebot tarama sıklığındaki değişim karşılaştırıldığında, erişilebilirlik sorunlarının tarama bütçesine olan etkisi ölçülür.
Search Console'un Tarama İstatistikleri raporundaki günlük tarama isteği sayısı, uptime monitörün kesinti kayıtlarıyla zaman damgası bazında eşleştirilir. Kesinti günlerinde tarama isteği sayısının düştüğü ve kurtarma sonrasında eski seviyeye dönmesinin kaç gün sürdüğü analiz edilir. LinkedIn üzerindeki teknik altyapı topluluklarında paylaşılan verilere göre, 2 saatten uzun kesintilerde tarama sıklığının eski seviyesine dönmesi ortalama 5 ila 10 gün sürmektedir. Bu gecikme, uptime izlemenin SEO stratejisindeki kritik konumunu doğrular.
Çoklu Endpoint İzleme Stratejisi
Tek bir URL izlemek site genelinin durumunu yansıtmaz. Farklı sunucu bileşenlerini test eden çoklu endpoint izleme yapılmalıdır:
- Ana sayfa kontrolü web sunucusu ve frontend bileşenlerinin çalıştığını doğrular, temel erişilebilirlik sinyali üretir.
- API health endpoint arka uç servislerinin ve veritabanı bağlantısının aktif olduğunu test eder, uygulama katmanı sorunlarını izole eder.
- Sitemap erişim kontrolü arama motoru tarayıcısının sitemap dosyasına ulaşabildiğini doğrular, tarama verimliliğini korur.
- Robots.txt erişimi tarayıcı yönlendirmelerinin sunulabildiğini kontrol eder, erişim engellendiğinde tüm tarama süreci durur.
- CDN origin kontrolü önbellek katmanını atlayarak sunucunun gerçek durumunu test eder, CDN maskelemesini ortadan kaldırır.
Incident Response ve Müdahale Süreci Dokümantasyonu
Kesinti tespit edildiğinde izlenecek adımların önceden belgelenmesi, müdahale süresini kısaltır. Panik anında doğaçlama karar vermek yerine standart bir müdahale protokolü izlenir.
Müdahale protokolü: birinci adımda kesintinin kapsamı belirlenir (tek sayfa mı, tüm site mi, belirli bölge mi). İkinci adımda kaynak tespit edilir (sunucu, veritabanı, DNS, CDN). Üçüncü adımda acil kurtarma uygulanır (servis yeniden başlatma, yedekten geri dönme, DNS değişikliği). Dördüncü adımda kurtarma doğrulanır ve uptime monitör üzerinden normal duruma dönüş teyit edilir. Beşinci adımda olay raporu (post-mortem) yazılır: ne oldu, neden oldu, ne yapıldı ve tekrarını önlemek için hangi önlemler alınacak.
Uptime Monitör Verilerinin Uzun Dönem Arşivlenmesi
Uptime verileri, hosting altyapısı kararlarını destekleyen stratejik bir veri kaynağıdır. Aylık ve yıllık uptime trendleri, sunucu değişikliği veya altyapı yükseltme kararlarında referans olarak kullanılır. Veriler minimum 24 ay boyunca arşivlenmelidir.
Arşivlenen veriler: her kesintinin başlangıç ve bitiş zamanı, süresi, etkilenen URL'ler, HTTP durum kodu, müdahale süresi ve kök neden analizi. Bu verilerin yapılandırılmış formatta (JSON veya CSV) saklanması, trend analizi ve raporlama için sorgulanabilir bir veri tabanı oluşturur. Yıllık uptime özet raporu, teknik altyapının performans karnesini sunar ve yatırım kararlarını somut veriye dayandırır.
🚀 Şimdi Harekete Geçin
Bu rehberi teori olmaktan çıkar — 5 farklı AI ile test et veya ekibinle paylaş.



