Article ve BlogPosting şemaları, web içeriklerinin yapısını, yazarını, yayıncısını ve yayın bilgilerini makine tarafından okunabilir formatta tanımlayan Schema.org yapısal veri türleridir. 2026 itibarıyla Google, yapısal veri içeren sayfaları zengin sonuçlarda (rich results) gösterme olasılığını artırmakta ve LLM tabanlı cevap motorları, yapısal veriden elde edilen bilgiyi kaynak güvenilirlik değerlendirmesinde doğrudan kullanmaktadır. Doğru uygulanmış Article schema'sı, sayfanın hem SERP görünürlüğünü hem de algoritmik güvenilirlik skorunu birlikte güçlendirir.
Article ve BlogPosting Türleri Arasındaki Teknik Fark
Schema.org hiyerarşisinde Article, CreativeWork sınıfının alt türüdür. BlogPosting ise Article'ın alt türüdür. Bu hiyerarşik ilişki, her BlogPosting'in aynı zamanda bir Article olduğu ancak her Article'ın bir BlogPosting olmadığı anlamına gelir. Haber makaleleri NewsArticle, akademik makaleler ScholarlyArticle, teknik dokümantasyon TechArticle olarak tanımlanırken, blog yazıları BlogPosting türünü kullanır.
Pratikte Google, Article ve BlogPosting arasında sıralama açısından fark gözetmez. Her iki tür de aynı zengin sonuç özelliklerini tetikler. Ancak semantik doğruluk, içeriğin algoritmik sınıflandırmasını etkiler. Blog sayfaları için BlogPosting, haber içerikleri için NewsArticle, genel makaleler için Article kullanmak, Google'ın içerik tipini doğru tanımasını sağlar. Yanlış tür seçimi doğrudan ceza üretmez ancak algoritmik anlama kalitesini düşürür.
JSON-LD Formatının Tercih Edilme Gerekçesi
Schema.org yapısal verisi üç formatta uygulanabilir: JSON-LD, Microdata ve RDFa. Google, resmi olarak JSON-LD formatını önerir. JSON-LD, HTML'den bağımsız bir <script> bloğunda yer alır ve sayfa yapısıyla iç içe geçmez. Bu ayrım, bakım kolaylığı, hata ayıklama ve dinamik oluşturma açısından avantaj sağlar.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "Makale Başlığı",
...
}
</script>
JSON-LD bloğu, <head> veya <body> bölümünde herhangi bir konuma yerleştirilebilir. SSR mimarilerinde sunucu tarafında render edilerek HTML'e dahil edilmesi, botun ilk tarama geçişinde yapısal veriyi okumasını garanti eder. JavaScript ile DOM'a enjekte edilen JSON-LD, render kuyruğu gecikmesiyle karşılaşabilir ve ilk geçişte okunamayabilir.
BlogPosting Schema'sının Zorunlu ve Önerilen Alanları
Google, BlogPosting schema'sında belirli alanları zorunlu, diğerlerini önerilen olarak sınıflandırır. Zorunlu alanlar eksik olduğunda yapısal veri geçersiz kabul edilir ve zengin sonuçlar tetiklenmez. Önerilen alanlar ise zengin sonuç kalitesini ve E-E-A-T sinyalini güçlendirir.
Zorunlu alanlar: headline (başlık), image (görsel) ve datePublished (yayın tarihi). Önerilen alanlar: author (yazar), dateModified (güncelleme tarihi), publisher (yayıncı), description (açıklama), mainEntityOfPage (ana sayfa referansı) ve articleBody veya wordCount (içerik bilgisi). Her önerilen alanın eklenmesi, yapısal verinin bilgi yoğunluğunu artırır ve algoritmik değerlendirmede daha güçlü sinyal üretir.
Tam Kapsamlı BlogPosting Schema Uygulaması
Tüm zorunlu ve önerilen alanları kapsayan eksiksiz bir BlogPosting schema uygulaması:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.example.com/blog/makale-basligi/"
},
"headline": "Makale Başlığı - Kısa ve Açıklayıcı",
"description": "Makalenin 150 karakterlik özeti",
"image": {
"@type": "ImageObject",
"url": "https://www.example.com/images/makale-gorseli.webp",
"width": 1200,
"height": 630
},
"author": {
"@type": "Person",
"name": "Yazar Adı Soyadı",
"url": "https://www.example.com/yazar/yazar-adi/",
"jobTitle": "Teknik SEO Uzmanı",
"sameAs": [
"https://www.linkedin.com/in/yazar-adi/",
"https://twitter.com/yazaradi"
]
},
"publisher": {
"@type": "Organization",
"name": "Marka Adı",
"logo": {
"@type": "ImageObject",
"url": "https://www.example.com/logo.png",
"width": 600,
"height": 60
}
},
"datePublished": "2026-04-13T10:00:00+03:00",
"dateModified": "2026-04-13T14:30:00+03:00",
"wordCount": 3500,
"articleSection": "Teknik SEO",
"keywords": ["crawl budget", "robots.txt", "teknik SEO"],
"inLanguage": "tr"
}
Bu yapıda her alan, belirli bir algoritmik sinyal taşır. mainEntityOfPage, bu schema'nın sayfanın birincil yapısal verisi olduğunu bildirir. image alanındaki boyut bilgileri, Google Discover ve sosyal medya paylaşımlarında görselin doğru render edilmesini sağlar. inLanguage alanı, içeriğin dilini algoritmik düzeyde bildirir.
Author Alanının E-E-A-T Sinyali Değeri
author alanı, BlogPosting schema'sının E-E-A-T bileşenlerini en güçlü biçimde besleyen alandır. Bu alanda yazar, bir Person entity olarak tanımlanır ve uzmanlık kanıtlarıyla desteklenir. name, url, jobTitle ve sameAs özellikleri, yazarın dijital kimliğini yapısal veri düzeyinde konsolide eder.
author.url alanı, yazarın biyografi sayfasına bağlantı vererek Google'ın yazar entity'sine ilişkin detaylı bilgiyi edinmesini sağlar. Bu URL, sitenin kendi yazar sayfasına işaret etmelidir; LinkedIn profiline yönlendirmek, entity sinyalini site dışına taşır. sameAs dizisi ise yazarın harici profillerini listeleyerek, farklı platformlardaki dijital ayak izinin tek entity'de birleşmesini destekler. Author alanının Person entity olarak tanımlanması, yalnızca isim string'i yazmaktan çok daha güçlü E-E-A-T sinyali üretir.
Publisher Alanı ve Organization Entity İlişkisi
publisher alanı, içeriği yayınlayan kuruluşu tanımlar. Bu alan, Organization türünde bir entity barındırır ve markanın adını, logosunu ve URL'sini bildirir. Publisher bilgisi, Google'ın içeriği hangi marka entity'siyle ilişkilendireceğini belirler.
Logo görseli, Google'ın yapısal veri yönergelerinde belirli gereksinimlere tabidir. Logo, dikdörtgen formatta ve minimum 112x112 piksel boyutunda olmalıdır. Çok geniş logolar (1200x60 gibi) desteklenmekle birlikte, kare veya kareye yakın formattaki logolar daha güvenilir render edilir. Logo URL'si, HTTPS üzerinden erişilebilir ve WebP, PNG veya JPEG formatında olmalıdır.
Publisher alanının site genelinde tutarlı biçimde uygulanması, tüm içeriklerin aynı Organization entity'sine bağlanmasını sağlar. Her makalede farklı publisher bilgisi kullanmak, entity konsolidasyonunu bozar. CMS'te publisher bilgisini merkezi bir yapılandırmadan çeken ve tüm sayfalara tutarlı biçimde uygulayan bir mekanizma kurulmalıdır.
datePublished ve dateModified Alanlarının Freshness Sinyali
datePublished, içeriğin ilk yayın tarihini; dateModified, içeriğin son güncelleme tarihini bildirir. Bu iki tarih, Google'ın freshness (tazelik) değerlendirmesinde doğrudan kullanılır. İçerik güncellendiğinde dateModified tarihi de güncellenmeli, ancak datePublished tarihi değiştirilmemelidir.
Tarih formatı ISO 8601 standardına uymalıdır: 2026-04-13T10:00:00+03:00. Saat dilimi bilgisi (+03:00 gibi) dahil edilmelidir; eksik saat dilimi, tarih yorumlamasında belirsizlik yaratır. dateModified tarihinin datePublished tarihinden önce olması mantıksal hatadır ve yapısal veri doğrulama uyarısı üretir. Her iki tarihin de sayfadaki görünür metin ile tutarlı olması zorunludur: schema'da 2026 tarihi bildirip sayfada "2024'te yayınlandı" yazmak, tutarsızlık uyarısı tetikler.
headline Alanı ve Title Etiketi İlişkisi
headline alanı, makalenin başlığını yapısal veri düzeyinde bildirir. Bu alan, HTML'deki <title> etiketi ve <h1> başlığıyla uyumlu olmalıdır. Google, headline alanını 110 karakter ile sınırlandırır; bu sınırı aşan başlıklar kesilir.
headline, <title> etiketinin birebir kopyası olmak zorunda değildir. <title> etiketi SERP'te CTR'ı optimize ederken marka adı ve format etiketi içerebilir: "Crawl Budget Optimizasyonu [2026 Rehber] | Seobaz". headline ise makalenin saf başlığını taşımalıdır: "Crawl Budget Optimizasyonu". Bu ayrım, her alanın kendi bağlamına uygun biçimde optimize edilmesini sağlar. H1 başlığı ile headline alanının birebir eşleşmesi ise en güvenli yaklaşımdır.
image Alanının Görsel SEO ve Discover Etkisi
image alanı, makalenin birincil görselini tanımlar. Bu görsel, Google Discover feed'inde, Google Haberler'de ve SERP'teki görsel kartlarda kullanılır. Google, minimum 1200 piksel genişliğinde görsel önerir; daha küçük görseller Discover'da gösterilmeyebilir.
Birden fazla görsel boyutu tanımlamak, farklı platformlarda doğru render'ı garanti eder:
"image": [
"https://www.example.com/images/gorsel-1200x630.webp",
"https://www.example.com/images/gorsel-1200x900.webp",
"https://www.example.com/images/gorsel-1200x1200.webp"
]
Bu üç boyut (16:9, 4:3, 1:1), Google'ın farklı bağlamlarda uygun formatı seçmesini sağlar. Discover için 1200x1200 kare format, SERP için 1200x630 geniş format tercih edilir. Görselin alt attribute'ü ve dosya adı, görsel SEO sinyallerini tamamlar.
articleSection ve keywords Alanlarının Tematik Sınıflandırma Etkisi
articleSection alanı, makalenin hangi site bölümüne ait olduğunu bildirir. "Teknik SEO", "İçerik Stratejisi", "Performans Optimizasyonu" gibi kategori bilgisi, Google'ın içeriği tematik olarak sınıflandırmasını destekler. Bu alan, sitenin topical authority yapısını yapısal veri düzeyinde yansıtır.
keywords alanı, makalenin hedeflediği anahtar kelimeleri listeler. Bu alan, Google'ın sıralama algoritmasında doğrudan ağırlık taşımaz ancak içeriğin konu kapsamını yapısal olarak bildirir. 3-5 anahtar kelime yeterlidir; 20+ anahtar kelime listesi, keyword stuffing algısı yaratır. Anahtar kelimeler, makalenin gerçek içeriğiyle tutarlı olmalıdır.
reviewedBy Alanı ve YMYL İnceleme Sinyali
YMYL kategorisindeki içeriklerde reviewedBy alanı, makalenin alanında uzman bir kişi tarafından incelendiğini bildirir. Bu alan, author alanından ayrıdır ve içeriğin üretimi ile doğrulamasının farklı kişiler tarafından yapıldığını gösterir:
"reviewedBy": {
"@type": "Person",
"name": "Dr. Uzman Adı",
"jobTitle": "Uzmanlık Alanı",
"url": "https://www.example.com/yazar/dr-uzman-adi/"
},
"lastReviewed": "2026-04-10"
lastReviewed alanı, incelemenin yapıldığı tarihi bildirir ve periyodik olarak güncellenmesi gereken bir alandır. Teknik SEO içerikleri doğrudan YMYL kategorisinde olmasa da, reviewedBy alanının eklenmesi güvenilirlik sinyalini farklılaştırıcı biçimde güçlendirir. Sahadaki gerçek tecrübemiz gösteriyor ki, reviewedBy alanını uygulayan teknik içerikler, uygulamayanlara kıyasla E-E-A-T değerlendirmesinde ölçülebilir avantaj sağlıyor.
citation Alanı ve Kaynak Referans Yapılandırması
citation alanı, makalede atıf yapılan kaynakları yapısal veri olarak tanımlar. Bu alan, metin içindeki outbound link'lerin yapısal karşılığıdır ve içeriğin kaynak ağını algoritmik düzeyde bildirir:
"citation": [
{
"@type": "WebPage",
"name": "Google Search Central - Yapısal Veri Rehberi",
"url": "https://developers.google.com/search/docs/appearance/structured-data"
},
{
"@type": "TechArticle",
"name": "Schema.org Article Type Hierarchy",
"url": "https://schema.org/Article"
}
]
Bu yapılandırma, Google'a içerik ile kaynak arasındaki ilişkiyi çift katmanlı biçimde bildirir: metin içi bağlantı + yapısal veri atıfı. LLM tabanlı cevap motorları, citation alanını kaynak güvenilirliği değerlendirmesinde doğrudan kullanır.
speakable Alanı ve Sesli Arama Uyumluluğu
speakable alanı, sayfadaki hangi bölümlerin sesli asistanlar (Google Assistant) tarafından okunmaya uygun olduğunu tanımlar. Bu alan, sesli arama sonuçlarında içeriğin alıntılanma olasılığını artırır:
"speakable": {
"@type": "SpeakableSpecification",
"cssSelector": [".article-summary", ".key-takeaway"]
}
cssSelector ile sayfadaki okunabilir bölümler CSS seçicileriyle işaretlenir. Bu bölümler, kısa ve öz biçimde bilgi sunan paragraflar olmalıdır. Uzun teknik açıklamalar sesli okumaya uygun değildir; 2-3 cümlelik özet paragraflar idealdir. Sesli arama hacmi artmaya devam ettikçe, speakable alanının stratejik değeri de artmaktadır.
isPartOf ve Blog Entity İlişkisi
isPartOf alanı, makalenin hangi blog veya yayın serisinin parçası olduğunu bildirir. Bu alan, bireysel makaleyi daha geniş bir içerik koleksiyonuna bağlar:
"isPartOf": {
"@type": "Blog",
"name": "Seobaz Teknik SEO Blogu",
"url": "https://www.example.com/blog/"
}
Bu ilişki, Google'ın blog'u bir entity olarak tanımasını ve blog altındaki tüm makaleleri bu entity'yle ilişkilendirmesini destekler. Topic cluster yapısında pillar page ve cluster page'ler arasındaki ilişki, isPartOf ile yapısal düzeyde teyit edilebilir.
breadcrumb ve Sayfa Hiyerarşisi Bildirimi
BreadcrumbList schema'sı, Article schema ile birlikte uygulandığında sayfanın site hiyerarşisindeki konumunu bildirir. Bu bildirim, SERP'te URL yerine breadcrumb yolunun görüntülenmesini sağlar ve kullanıcıya sayfanın bağlamını sunar:
{
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "Ana Sayfa",
"item": "https://www.example.com/"
},
{
"@type": "ListItem",
"position": 2,
"name": "Blog",
"item": "https://www.example.com/blog/"
},
{
"@type": "ListItem",
"position": 3,
"name": "Teknik SEO",
"item": "https://www.example.com/blog/teknik-seo/"
}
]
}
SERP'te breadcrumb görünümü, URL'nin ham formundan daha okunabilir ve güvenilirdir. Kullanıcı, "example.com > Blog > Teknik SEO" yolunu gördüğünde, sayfanın bağlamını anında kavrar. Bu kavrama, dolaylı olarak CTR'ı artırır.
WordPress'te Article/BlogPosting Schema Entegrasyonu
WordPress ekosisteminde Yoast SEO ve Rank Math eklentileri, Article ve BlogPosting schema'sını otomatik olarak uygular. Her iki eklenti de yazı yayınlandığında JSON-LD bloğunu HTML'e ekler ve zorunlu alanları (headline, image, datePublished, author, publisher) otomatik olarak doldurur.
Ancak eklenti otomasyonunun sınırları vardır. reviewedBy, citation, speakable ve articleSection gibi ileri düzey alanlar, standart eklenti yapılandırmasında yer almaz. Bu alanların eklenmesi, eklentinin "özel schema" özelliği veya functions.php dosyasında manuel JSON-LD enjeksiyonu ile sağlanır. Eklentinin ürettiği schema çıktısını Google Rich Results Test ile doğrulamak, her eklenti güncellemesinden sonra zorunlu bir kontrol adımıdır.
Next.js ve Headless CMS'lerde Schema Uygulaması
Next.js, Nuxt.js ve Gatsby gibi headless mimarilerde schema, bileşen düzeyinde veya layout düzeyinde uygulanır. Next.js'te JSON-LD, <script> etiketi olarak bileşen return'ünde yer alır:
export default function BlogPost({ post }) {
const jsonLd = {
'@context': 'https://schema.org',
'@type': 'BlogPosting',
headline: post.title,
image: post.featuredImage,
datePublished: post.publishDate,
dateModified: post.modifiedDate,
author: {
'@type': 'Person',
name: post.author.name,
url: `/yazar/${post.author.slug}/`
},
publisher: {
'@type': 'Organization',
name: 'Marka Adı',
logo: { '@type': 'ImageObject', url: '/logo.png' }
}
};
return (
<>
<script
type="application/ld+json"
dangerouslySetInnerHTML={{ __html: JSON.stringify(jsonLd) }}
/>
<article>{/* İçerik */}</article>
</>
);
}
Bu yapıda schema, sunucu tarafında render edilerek HTML'e dahil edilir. CMS verilerinden dinamik olarak oluşturulan schema alanları, her makale için benzersiz ve doğru bilgi barındırır. Bu otomasyon, büyük içerik envanterlerinde manuel schema yönetiminin pratik olmadığı durumlarda sürdürülebilir çözüm sunar.
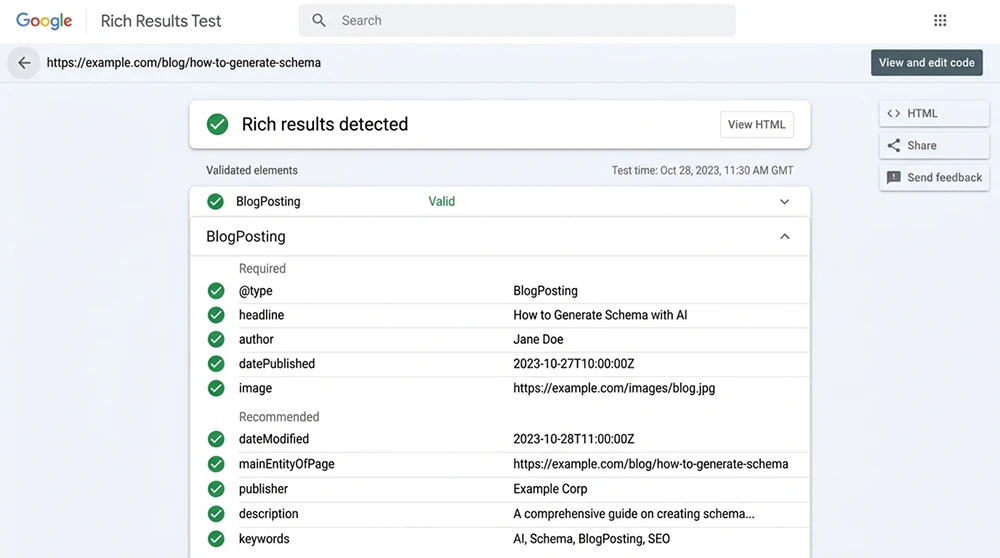
Google Rich Results Test ile Schema Doğrulaması
Schema uygulamasının doğruluğu, Google Rich Results Test aracıyla doğrulanmalıdır. Bu araç, sayfadaki yapısal veriyi parse eder, zorunlu alan eksikliklerini ve sözdizimi hatalarını raporlar ve zengin sonuç önizlemesini gösterir. URL veya kod yapıştırma yöntemiyle test yapılabilir.
Doğrulama sürecinde dikkat edilmesi gereken noktalar: tüm zorunlu alanların yeşil onay alması, uyarı (warning) mesajlarının incelenmesi ve önizlemenin beklenen görünümle eşleşmesi. Uyarılar hata değildir ancak zengin sonuç kalitesini düşürebilir. Önerilen alanların eksikliği uyarı olarak raporlanır; bu uyarıları gidermek, zengin sonuç potansiyelini artırır. Her schema değişikliğinden sonra ve her CMS eklenti güncellemesinden sonra Rich Results Test ile doğrulama yapmak, yapısal veri hijyeninin temel kuralıdır.
Schema Hataları ve Yaygın Uygulama Yanlışları
Schema uygulamasında tekrarlanan hatalar, zengin sonuçların kaybolmasına veya hiç tetiklenmemesine neden olur. En yaygın hata, image alanının eksik bırakılmasıdır; Google, görselsiz BlogPosting schema'sını geçersiz kabul eder. İkinci yaygın hata, datePublished tarihinin yanlış formatta yazılmasıdır; "13 Nisan 2026" yerine "2026-04-13T10:00:00+03:00" ISO 8601 formatı kullanılmalıdır.
Üçüncü hata, author alanının yalnızca isim string'i olarak tanımlanmasıdır. "author": "Yazar Adı" yerine "author": {"@type": "Person", "name": "Yazar Adı"} kullanılmalıdır. Dördüncü hata, publisher.logo boyutlarının Google yönergelerine uymamasıdır. Çok büyük veya çok küçük logolar, zengin sonuçlarda render sorunları yaratır. Beşinci hata, sayfada birden fazla çelişen schema bloğu bulunmasıdır. Eklenti otomatik schema üretirken, tema veya ek eklenti de ayrı schema ekliyorsa, çift schema çakışması oluşur.
NewsArticle ve Article Arasındaki Stratejik Seçim
Haber ve güncel içerik üreten siteler için NewsArticle türü, Article veya BlogPosting yerine tercih edilmelidir. NewsArticle, Google Haberler'de görünme, Top Stories karuseline dahil olma ve haber zengin sonuçlarını tetikleme potansiyeli taşır. Ancak NewsArticle, Google Haberler yayıncı politikalarına uyumlu sitelerde etkilidir; bu politikalara uygun olmayan sitelerde NewsArticle kullanmak ek avantaj sağlamaz.
BlogPosting, düzenli blog yazıları, rehber içerikler ve uzun form makaleler için ideal türdür. Article, daha genel bir sınıflandırma olup blogpost dışındaki makale formatları (araştırma raporları, white paper'lar, teknik dokümanlar) için uygundur. Seçim, içeriğin gerçek türüne göre yapılmalıdır; yanlış tür kullanmak semantik tutarsızlık yaratır.
Çoklu Schema Türlerinin Birlikte Kullanımı
Bir sayfada birden fazla schema türü birlikte uygulanabilir. BlogPosting schema'sı ile BreadcrumbList, FAQPage ve HowTo schema'ları aynı sayfada yer alabilir. Her schema türü, sayfanın farklı bir boyutunu tanımlar ve farklı bir zengin sonuç türünü tetikleme potansiyeli taşır.
[
{
"@type": "BlogPosting",
"headline": "...",
...
},
{
"@type": "BreadcrumbList",
"itemListElement": [...]
},
{
"@type": "FAQPage",
"mainEntity": [...]
}
]
Birden fazla schema türü, tek bir JSON-LD bloğunda dizi olarak veya ayrı <script> bloklarında sunulabilir. Her iki yaklaşım da geçerlidir. Ancak aynı sayfada çelişen schema türleri (örneğin hem Product hem BlogPosting) kullanmak, semantik tutarsızlık yaratır ve algoritmik değerlendirmeyi olumsuz etkiler.
Schema ve LLM Alıntılama İlişkisi
LLM tabanlı cevap motorları, yapısal veriyi kaynak güvenilirlik değerlendirmesinde kullanır. author alanında Person entity tanımlı olan, publisher alanında Organization entity barındıran ve citation alanında otoriter kaynaklar referans verilen içerikler, yapısal veri olmayan içeriklere kıyasla daha yüksek güvenilirlik skoru alır.
Bu ilişki, GEO (Generative Engine Optimization) stratejisinin yapısal veri boyutunu oluşturur. LinkedIn üzerindeki GEO topluluklarında paylaşılan alıntılama analizleri gösteriyor ki, tam kapsamlı Article schema uygulayan sayfaların LLM alıntılanma oranı, schema uygulamayan sayfalara kıyasla ortalama %25-35 daha yüksek. Bu veri, yapısal verinin yalnızca klasik SERP değil, AI cevap motorlarında da güvenilirlik sinyali olarak işlev gördüğünü doğrular.
Schema Bakımı ve Periyodik Doğrulama Döngüsü
Çoğu uzman aksini iddia etse de, schema uygulaması "bir kez yap ve unut" yaklaşımıyla yönetilemez. CMS eklenti güncellemeleri, tema değişiklikleri, yazar bilgisi değişiklikleri ve Google'ın yapısal veri yönerge revizyonları, mevcut schema'yı geçersiz hale getirebilir. Yoast SEO veya Rank Math güncellemesinden sonra schema çıktısının değişmesi, sık karşılaşılan bir senaryodur.
Schema bakımı üç katmanlı döngüyle yönetilmelidir. Birincisi, her CMS eklenti güncellemesinden sonra Rich Results Test ile doğrulama. İkincisi, üç aylık periyotlarla tüm sayfa türlerinin (blog, hizmet, ürün, yazar) schema çıktılarının örneklem kontrolü. Üçüncüsü, Google'ın yapısal veri yönerge değişikliklerinin izlenmesi ve mevcut schema'nın yeni yönergelere uyumluluğunun doğrulanması.
Article Schema Kontrol Listesi ve Uygulama Standartları
Her teknik denetimde uygulanması gereken schema kontrol noktaları şunlardır:
- Zorunlu alanların eksiksiz olduğunu doğrulayın: headline, image ve datePublished alanlarının her makalede tanımlı olduğunu Rich Results Test ile kontrol edin.
- Author alanının Person entity olarak tanımlandığını teyit edin: String yerine @type: Person yapısı kullanıldığını, name, url ve sameAs alanlarının dolu olduğunu doğrulayın.
- Publisher bilgisinin site genelinde tutarlı olduğunu kontrol edin: Tüm sayfalarda aynı Organization name ve logo kullanıldığını doğrulayın.
- datePublished ve dateModified tutarlılığını kontrol edin: Schema tarihleri ile sayfada görünür tarihler arasında uyumsuzluk olmadığını teyit edin.
- image alanının Google Discover gereksinimlerini karşıladığını doğrulayın: Minimum 1200px genişlik ve tercihen birden fazla aspect ratio sunulduğunu kontrol edin.
- Çift schema çakışmasının olmadığını kontrol edin: Eklenti ve tema kaynaklı mükerrer schema blokları bulunmadığını doğrulayın.
Schema Uygulamasının Uzun Vadeli Yönetimi
İşin mutfağında durum farklıdır: schema uygulaması, sayfanın algoritmik kimlik kartıdır. Bu kimlik kartındaki bilgiler eksik, yanlış veya tutarsız olduğunda, sayfanın algoritmik değerlendirmesi zayıflar. Zengin sonuçlar kaybolur, E-E-A-T sinyalleri yapısal düzeyde desteklenmez ve LLM alıntılama potansiyeli düşer.
Teoride doğru görünen ama pratikte patlayan nokta şudur: schema uygulamasının teknik doğruluğu kadar, içerikle tutarlılığı da kritiktir. Schema'da "author: Dr. Uzman" yazıp sayfada yazar bilgisi göstermemek, yapısal veri manipülasyonudur ve tespit edildiğinde güvenilirlik kaybına neden olur. Schema'daki her alan, sayfadaki görünür içerikle birebir tutarlı olmalıdır. Bu tutarlılık, yapısal verinin algoritmik sinyalini güçlendiren temel ilkedir. Schema, sayfanın makine tarafından okunabilir özeti olarak, sayfanın gerçeğini yansıtmalıdır; gerçeğin üzerine çıkmamalıdır.