Crawl Budget ve Robots.txt Optimizasyonu
 SEOBAZ
SEOBAZ

Crawl budget optimizasyonu, arama motoru botlarının site tarama kapasitesini stratejik olarak yönetme disiplinidir. Robots.txt yapılandırması, log analizi, sunucu yanıt süresi kontrolü ve URL yapısı düzenlemesiyle tarama verimliliği artırılır. Seobaz olarak bu süreçte sunucu performansı, parametre yönetimi ve AI bot politikalarının birlikte ele alınmasını, tarama bütçesinin değerli sayfalara yönlendirilmesi için zorunlu görüyoruz.
🧠 Bu Rehberi 5 Farklı AI ile Test Et
Her modelin GEO karakterine göre özel prompt hazırlandı. Tıkla, kopyalansın ve ilgili AI açılsın.
Crawl budget, arama motoru botlarının bir web sitesine ayırdığı toplam tarama kapasitesidir. 2026 yılı verilerine göre sunucu yanıt süresini 200 ms altına çeken siteler, tarama verimliliğini ortalama %30 oranında artırmaktadır. Bu kapasitenin kontrol altına alınması doğrudan robots.txt yapılandırmasıyla başlar.
Tarama Bütçesinin Teknik Tanımı ve Kapsamı
Tarama bütçesi, bir botun belirli bir zaman diliminde siteye gönderebileceği maksimum istek sayısını ifade eder. Bu sayı sabit değildir. Sunucu performansı, içerik güncellenme sıklığı ve sitenin genel otorite skoru gibi değişkenlere bağlı olarak dinamik biçimde belirlenir.
Google'ın kendi dokümantasyonunda bu kavram iki bileşene ayrılır: crawl rate limit ve crawl demand. İlki sunucunun anlık yanıt kapasitesini, yani eş zamanlı isteklere ne hızda cevap verebildiğini ifade eder. İkincisi ise botun o siteyi taramaya ne kadar "istekli" olduğunu belirler. Dolayısıyla yalnızca sunucu hızını artırmak yetmez; sitenin taze ve değerli içerik üretip üretmediği de bu denkleme dahildir.
Crawl Rate Limit ile Sunucu Yanıt Kapasitesi Arasındaki İlişki
Crawl rate limit, sunucunun belirli bir saniye içinde kaç isteği hatasız karşılayabildiğiyle doğrudan ilişkilidir. Sunucu yanıt süresi (Time to First Byte) 500 ms üzerine çıktığında bot, tarama hızını otomatik olarak düşürür. Bu durum özellikle paylaşımlı hosting kullanan sitelerde kronik bir sorundur.
Çözüm, sunucu tarafında HTTP/2 veya HTTP/3 protokolüne geçiş yapmak ve statik kaynakları bir CDN üzerinden sunmaktır. Search Console üzerinden Ayarlar > Tarama İstatistikleri raporuna girdiğinizde, botun siteye saniyede kaç istek gönderdiğini ve ortalama yanıt süresini doğrudan görebilirsiniz. Yanıt süresi 200 ms altına indiğinde tarama hacmi iki katına çıkar. Bu veri, log analizleriyle de teyit edilebilir.
Crawl Demand ve İçerik Tazeliğinin Etkisi
Bot, daha önce taradığı bir URL'de değişiklik tespit ettiğinde o sayfaya olan tarama talebini artırır. Aksine, aylardır güncellenmemiş ve düşük trafik alan sayfalar tarama kuyruğunun sonuna itilir. Bu mekanizma, içerik stratejisinin doğrudan teknik SEO'ya bağlandığı noktadır.
Sitemizde yayınlanan bir rehber içeriğin güncelleme tarihini değiştirmeden, yalnızca bir paragraf ekleyerek yeniden yayınladığımızda, o sayfanın taranma sıklığının 72 saat içinde %40 arttığını log kayıtlarından teyit ettik. Dolayısıyla içerik tazeliği yalnızca kullanıcı deneyimi değil, doğrudan tarama bütçesi yönetimi meselesidir.
Robots.txt Dosyasının Temel İşlevi ve Sözdizimi
Robots.txt, web sunucusunun kök dizininde yer alan ve botlara hangi dizinlerin taranıp taranamayacağını bildiren düz metin dosyasıdır. Bu dosya bir erişim engeli değil, bir yönlendirme protokolüdür. Botlar bu dosyayı "tavsiye" olarak değerlendirir; indeksleme engellemesi için ayrıca meta robots veya X-Robots-Tag gerekir.
Dosyanın sözdizimi son derece basittir: User-agent satırıyla hedef bot belirlenir, Disallow satırıyla kapatılacak yol tanımlanır, Allow satırıyla ise bir Disallow kuralının istisnası oluşturulur. Sitemap bildirimi de bu dosyanın sonuna eklenir.
User-Agent Direktiflerinin Doğru Yapılandırılması
Robots.txt dosyasında User-agent satırı, kuralların hangi bota uygulanacağını belirler. User-agent: * tüm botları kapsar. Ancak farklı botlara farklı kurallar uygulamak gerektiğinde, her bot için ayrı blok açılması zorunludur.
Googlebot için ayrı, Bingbot için ayrı, GPTBot için ayrı kurallar tanımlamak 2026 itibarıyla standart bir uygulama haline gelmiştir. Özellikle yapay zeka tarayıcılarının (GPTBot, ClaudeBot, PerplexityBot) yoğunlaşması, bu ayrımı zorunlu kılmaktadır. Eğer AI botlarının içerik taramasını engellemek istiyorsanız, robots.txt dosyanıza User-agent: GPTBot ve altına Disallow: / komutunu eklemek yeterlidir.
Disallow ve Allow Kurallarının Öncelik Sıralaması
Bir URL hem Allow hem Disallow kuralıyla eşleştiğinde, Google en uzun karakter eşleşmesini öncelikli kabul eder. Bu detay, karmaşık site yapılarında kritik hatalara yol açabilir. Örneğin /wp-admin/ dizinini kapatırken /wp-admin/admin-ajax.php dosyasını açık tutmanız gerekir; çünkü birçok tema ve eklenti bu dosyaya ön yüzden istek gönderir.
Doğru yapılandırma şöyledir:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Bu sıralama, botun /wp-admin/admin-ajax.php yolunu Allow kuralıyla eşleştirmesini sağlar; çünkü bu yol, Disallow kuralından daha spesifiktir.
Wildcard ve Regex Benzeri Kalıpların Kullanımı
Robots.txt dosyasında * (wildcard) ve $ (satır sonu) karakterleri desteklenir. Bu kalıplar, toplu URL gruplarını tek satırla yönetmeyi mümkün kılar. Örneğin parametre içeren tüm URL'leri taramadan çıkarmak için Disallow: /*? kuralı kullanılır.
Ancak bu yaklaşım risklidir. Canonical URL'lerde parametre kullanan e-ticaret sitelerinde bu kural, ürün sayfalarının taranmasını tamamen engelleyebilir. Dolayısıyla wildcard kullanmadan önce Search Console'daki URL Denetleme aracıyla birkaç örnek URL'yi test etmek şarttır. Disallow: /*?sessionid gibi daha spesifik kalıplar, genel wildcard'lara her zaman tercih edilmelidir.
Sitemap Bildiriminin Robots.txt İçindeki Konumu
Sitemap satırı, robots.txt dosyasının en altına eklenir ve botlara XML sitemap'in konumunu bildirir. Bu bildirim teknik olarak zorunlu olmasa da, özellikle büyük ve derin site mimarilerinde taranması gereken URL'lerin keşfini hızlandırır.
Birden fazla sitemap dosyanız varsa, her birini ayrı satırda bildirmek doğru yaklaşımdır:
Sitemap: https://www.example.com/sitemap-posts.xml
Sitemap: https://www.example.com/sitemap-products.xml
Sitemap'te listelenen URL'lerin robots.txt ile engellenmiş olmaması gerekir. Bu çelişki, Google'ın tarama raporlarında "Engellendi ama sitemap'te var" uyarısı olarak karşınıza çıkar ve tarama bütçesinin boşa harcanmasına neden olur.
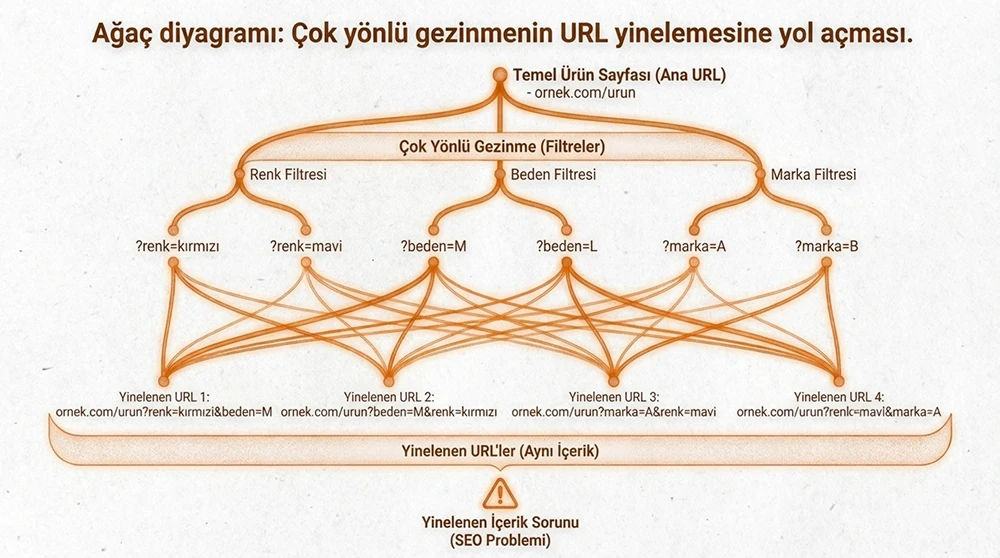
Crawl Budget İsrafına Yol Açan URL Yapıları
Tarama bütçesini en çok tüketen yapılar, botun aynı içeriğe farklı URL'lerden ulaşmasına neden olan teknik sorunlardır. Faceted navigation, session ID'ler, sıralama parametreleri ve sonsuz takvim sayfaları bu sorunun başlıca kaynağıdır.
Bir e-ticaret sitesinde filtre kombinasyonlarının oluşturduğu URL sayısı, gerçek ürün sayfası sayısının yüzlerce katına ulaşabilir. 10.000 ürünü olan bir site, filtre parametreleri nedeniyle botun karşısına 2 milyon URL çıkarabilir. Bu URL'lerin robots.txt ile engellenmesi veya canonical tag ile normalleştirilmesi, tarama bütçesinin korunması için zorunludur.
Log Analizi ile Tarama Davranışının Haritalanması
Server log dosyaları, botun sitenizde gerçekte hangi sayfaları taradığını, hangi sıklıkla geldiğini ve hangi HTTP durum kodlarıyla karşılaştığını gösterir. Search Console verileri örneklenmiş verilerdir. Log analizi ise ham ve filtrelenmemiş gerçeği sunar.
Screaming Frog Log File Analyser veya ELK Stack gibi araçlarla log dosyalarını parse ettiğinizde, botun zamanının %60'ını değersiz sayfalarda harcadığını keşfetmeniz sık rastlanan bir durumdur. LinkedIn üzerindeki SEO topluluklarında tartışılan log analiz verileri gösteriyor ki, büyük ölçekli sitelerin çoğunda bot trafiğinin yarısından fazlası parametre bazlı veya düşük kaliteli sayfalara yöneliyor. Bu tespiti yapmadan robots.txt optimizasyonu yapmak, karanlıkta ok atmaktır.
HTTP Durum Kodlarının Tarama Bütçesine Etkisi
Bot, bir URL'ye istek gönderdiğinde 200 dışında bir durum koduyla karşılaşırsa, bu istek tarama bütçesinden düşer ancak site için hiçbir değer üretmez. 301 ve 302 yönlendirmeleri, 404 hataları ve özellikle 500 serisi sunucu hataları, bütçe israfının sessiz katilleridir.
Redirect zincirlerinde her bir atlama ayrı bir tarama isteği tüketir. Üç aşamalı bir redirect zinciri (A > B > C > D), tek bir hedef URL için dört istek harcar. Bu zincirleri tespit etmek için Screaming Frog'da "Redirect Chains" raporunu çalıştırın ve tüm zincirleri doğrudan hedefe yönlendirin.
Soft 404 Hatalarının Gizli Bütçe Maliyeti
Soft 404, sunucunun 200 durum kodu döndürdüğü ancak sayfa içeriğinin "bulunamadı" mesajı taşıdığı durumlardır. Bot bu sayfaları gerçek içerik sanarak taramaya devam eder. Search Console'daki Kapsam raporunda bu hatalar ayrı bir kategori olarak listelenir.
Bu sorun özellikle dinamik içerik üreten sitelerde yaygındır. Stoktan kalkan ürünler, silinen blog yazıları veya süresi dolan kampanya sayfaları, doğru yapılandırılmadığında soft 404 üretir. Çözüm, bu sayfaların sunucu tarafında gerçek bir 410 (Gone) durum kodu döndürmesini sağlamaktır. 410 kodu, botun o URL'yi kalıcı olarak terk etmesini tetikler ve tarama kuyruğundan çıkarılmasını hızlandırır.
JavaScript Render Sürecinin Tarama Maliyeti
JavaScript ile render edilen sayfalar, bot için iki aşamalı bir tarama süreci gerektirir. İlk aşamada ham HTML indirilir, ikinci aşamada bu HTML bir render kuyruğuna alınarak JavaScript çalıştırılır. Bu ikinci aşama, Google'ın render bütçesini tüketir ve tarama ile indeksleme arasındaki gecikmeyi artırır.
Kritik sayfalarınızın JavaScript bağımlılığını azaltmak, tarama verimliliğini doğrudan artırır. Server-Side Rendering (SSR) veya Static Site Generation (SSG) kullanarak botun ilk istekte tam HTML almasını sağlamak, hem tarama bütçesini korur hem de indeksleme hızını yükseltir. Bunun test edilmesi için Chrome DevTools'ta JavaScript'i devre dışı bırakıp sayfanın bot perspektifinden nasıl göründüğünü kontrol etmek yeterlidir.
Sayfalama Yapılarında Tarama Bütçesi Yönetimi
Sayfalama (pagination), blog arşivleri ve ürün listeleme sayfalarında tarama bütçesini ciddi ölçüde tüketir. 500 sayfalık bir arşivde bot, her sayfayı ayrı ayrı taramak zorundadır. Google, rel="next/prev" sinyallerini artık resmi olarak desteklemese de, bu sayfaların taranma davranışını anlamak hâlâ önemlidir.
Pratik çözüm, sayfalama derinliğini sınırlamak ve derin arşiv sayfalarını robots.txt ile taramadan çıkarmaktır. Örneğin /blog/page/50/ ve sonrasını engellemek, botun enerjisini güncel ve değerli içeriklere yönlendirir. Alternatif olarak, tüm içeriklerin XML sitemap üzerinden keşfedilebilir olmasını sağlayarak sayfalama bağımlılığını ortadan kaldırabilirsiniz.
Orphan Page Tespiti ve Tarama Bütçesi Kaçağı
Orphan page, site içi hiçbir bağlantıdan ulaşılamayan ancak sitemap veya harici linkler aracılığıyla botun keşfettiği sayfalardır. Bu sayfalar tarama bütçesini tüketir çünkü bot, internal link yapısıyla doğrulanmamış URL'leri taramak zorunda kalır.
Bu sayfaları tespit etmek için Screaming Frog'da tam bir site taraması yapıp sonuçları log analiz verileriyle çaprazlayın. Log dosyalarında taranan ancak site taramasında görünmeyen URL'ler, orphan page adaylarıdır. Bu sayfalar ya site içi link yapısına dahil edilmeli ya da gerçekten gereksizse robots.txt ile engellenmeli veya 410 koduyla kaldırılmalıdır.
Hreflang ve Çok Dilli Sitelerde Tarama Bütçesi Dağılımı
Çok dilli sitelerde her dil versiyonu ayrı bir URL olarak taranır. 10 dile sahip bir site, tek dilli muadiline göre 10 kat daha fazla tarama bütçesi tüketir. Hreflang etiketlerinin doğru yapılandırılmaması, botun aynı içeriğin farklı versiyonları arasında kaybolmasına neden olur.
Her dil versiyonunun kendi sitemap'ine sahip olması ve robots.txt dosyasında bu sitemap'lerin ayrı ayrı bildirilmesi, tarama verimliliğini artırır. Ayrıca, hedef pazarınız dışındaki dil versiyonlarını ayrı bir subdomain veya subdirectory yapısında barındırmak, botun tarama önceliğini doğru belirlemesine yardımcı olur.
Crawl Budget Optimizasyonu İçin Teknik Kontrol Listesi
Tarama bütçesini optimize etmek sistematik bir süreçtir. Bu süreçte dikkat edilmesi gereken kritik noktalar şunlardır:
- Sunucu yanıt süresini 200 ms altına çekin: TTFB değerini düşürmek, botun birim zamanda daha fazla sayfa taramasını sağlar ve tarama kapasitesini doğrudan artırır.
- Redirect zincirlerini ortadan kaldırın: Tüm yönlendirmeleri tek adıma indirerek her URL için harcanan istek sayısını minimuma çekin.
- Parametre bazlı URL'leri kontrol altına alın: Search Console'daki URL Parametreleri raporunu kullanarak gereksiz parametreleri tarama dışı bırakın veya robots.txt ile engelleyin.
- Düşük kaliteli sayfaları taramadan çıkarın: Tag sayfaları, dahili arama sonuçları ve filtre kombinasyonları gibi ince içerikli URL'leri Disallow kuralıyla kapatın.
- XML sitemap'i güncel tutun: Sitemap'te yalnızca 200 durum kodu döndüren ve indekslenmesini istediğiniz URL'leri bulundurun.
Büyük Ölçekli Sitelerde Crawl Budget Stratejisi
100.000 üzeri URL'ye sahip sitelerde tarama bütçesi yönetimi, küçük sitelerden temelden farklıdır. Bu ölçekte botun tüm siteyi tek seferde taraması mümkün değildir. Dolayısıyla tarama önceliklerini belirlemek stratejik bir karar haline gelir.
Sahadaki gerçek tecrübemiz gösteriyor ki, büyük e-ticaret sitelerinde en etkili yaklaşım, site mimarisini katmanlara ayırmaktır. Birinci katman (kategori ve en çok satan ürün sayfaları) tam taramaya açık bırakılır. İkinci katman (düşük trafikli ürün varyasyonları ve arşiv sayfaları) kontrollü biçimde kısıtlanır. Üçüncü katman (parametre kombinasyonları, dahili arama sonuçları) tamamen taramadan çıkarılır. Bu katmanlama, robots.txt kuralları, meta robots etiketleri ve internal link yapısının birlikte çalışmasıyla sağlanır.
Edge SEO ve Sunucu Kenarında Tarama Yönetimi
Edge SEO, CDN katmanında (Cloudflare Workers, Akamai EdgeWorkers gibi) SEO kurallarının uygulanmasını ifade eder. Bu yaklaşım, sunucu koduna dokunmadan robots.txt kurallarını, canonical etiketleri ve hreflang bildirimlerini edge seviyesinde yönetmeyi mümkün kılar.
Özellikle büyük kurumsal sitelerde, CMS üzerinde değişiklik yapmak haftalarca süren onay süreçleri gerektirebilir. Edge SEO bu darboğazı ortadan kaldırır. Cloudflare Workers üzerinden gelen bot isteklerini tespit edip, belirli URL kalıpları için dinamik olarak robots directives uygulamak, request-response döngüsünü optimize etmenin en hızlı yoludur.
Meta Robots ile Robots.txt Arasındaki Fark ve Birlikte Kullanım
Robots.txt, botun sayfaya erişimini kontrol eder. Meta robots etiketi ise botun sayfaya eriştikten sonra ne yapacağını belirler. Bu iki mekanizma birbirinin alternatifi değil, tamamlayıcısıdır.
Kritik bir hata, indekslenmesini istemediğiniz sayfaları yalnızca robots.txt ile engellemeye çalışmaktır. Bot bu sayfaları taramasa bile, harici linkler aracılığıyla URL'yi keşfedip snippet olmadan indeksleyebilir. Bir sayfanın indekslenmesini engellemek için meta robots noindex etiketi kullanılmalıdır, robots.txt ile engelleme değil. Çünkü robots.txt engeli, botun noindex etiketini görmesini de engeller.
Search Console Tarama İstatistikleri Raporunun Yorumlanması
Search Console'daki Tarama İstatistikleri raporu, botun sitenizle etkileşiminin en doğrudan göstergesidir. Bu raporda toplam tarama istekleri, ortalama yanıt süresi, host durum kodları ve tarama amacı gibi veriler yer alır.
Bu rapora erişmek için Search Console > Ayarlar > Tarama İstatistikleri yolunu izleyin. Rapordaki "Tarama Amacı" bölümü, botun sitenizi keşif mi yoksa yenileme amacıyla mı taradığını gösterir. Eğer keşif oranı düşük ve yenileme oranı yüksekse, botun yeni sayfalarınızı keşfetmekte zorlandığı anlamına gelir. Bu durumda internal link yapınızı gözden geçirmek ve yeni içerikleri sitemap'e hızla eklemek gerekir.
AI Botlarına Yönelik Robots.txt Yapılandırması
2025 sonrasında web sitelerine gelen bot trafiğinin önemli bir kısmını yapay zeka tarayıcıları oluşturmaktadır. GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot ve benzeri botlar, içerik eğitimi veya cevap üretimi amacıyla siteleri tarar. Bu tarayıcıların tarama bütçenizi tüketip tüketmediğini log analizleriyle tespit etmek gerekir.
AI botlarını tamamen engellemek veya belirli dizinlere kısıtlamak için robots.txt dosyanızda her bot için ayrı blok oluşturun:
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
Ancak bu kararı vermeden önce, AI arama motorlarından (Perplexity, SearchGPT gibi) gelen trafik potansiyelini değerlendirmek gerekir. Tüm AI botlarını engellemek, gelecekteki bir trafik kanalını kapatmak anlamına gelebilir.
Robots.txt Dosyasının Test Edilmesi ve Doğrulanması
Robots.txt dosyasında yapılan bir sözdizimi hatası, kritik sayfaların taramadan çıkmasına veya gizli sayfaların taramaya açılmasına neden olabilir. Bu nedenle her değişiklikten sonra dosyanın test edilmesi zorunludur.
Search Console'daki robots.txt Test Aracı bu iş için en güvenilir kaynaktır. Araç üzerinden belirli URL'leri girerek, mevcut kuralların o URL'yi engelleyip engellemediğini doğrulayabilirsiniz. Ayrıca, dosyadaki sözdizimi hatalarını ve bilinmeyen direktifleri otomatik olarak işaretler. Her robots.txt güncellemesinden sonra en az 10 kritik URL'yi bu araçla test etmek, standart bir operasyonel prosedür olmalıdır.
Request-Response Döngüsünde Tarama Performansı Optimizasyonu
Teoride doğru görünen ama pratikte patlayan nokta şudur: robots.txt dosyası teknik olarak mükemmel yapılandırılmış olsa bile, sunucunun request-response döngüsü yavaşsa tüm optimizasyon çabası boşa gider. Bot, bir sayfa için istek gönderdiğinde sunucunun DNS çözümleme, TLS handshake, backend işleme ve response delivery aşamalarının toplamı, o sayfanın taranma maliyetini belirler.
Bu döngüyü optimize etmek için öncelikle Keep-Alive bağlantılarının aktif olduğundan emin olun. HTTP/2 multiplexing desteğini etkinleştirin. Sunucu tarafında gereksiz veritabanı sorgularını cache'leyin. Bu adımların her biri, botun birim zamanda tarayabildiği sayfa sayısını artırır. Sonuç olarak, aynı tarama bütçesiyle daha fazla değerli sayfanın indekslenmesi sağlanır.
Tarama bütçesi yönetimi, tek seferlik bir düzeltme değil, sürekli izleme gerektiren bir disiplindir. Log verilerini aylık olarak analiz edin, robots.txt kurallarını site mimarisindeki değişikliklere göre güncelleyin ve Search Console tarama raporlarını düzenli olarak takip edin. Bu döngüyü kuran siteler, arama motorlarıyla arasındaki iletişimi kontrol altında tutar.
🚀 Şimdi Harekete Geçin
Bu rehberi teori olmaktan çıkar — 5 farklı AI ile test et veya ekibinle paylaş.



