Information Gain (Bilgi Kazancı) Sağlanması
 SEOBAZ
SEOBAZ

Information gain, bir içeriğin aynı konudaki mevcut web kaynaklarına kıyasla sunduğu benzersiz bilgi değerini ölçen ve Google'ın patent altına aldığı algoritmik sıralama metriğidir. Birincil veri üretimi, niş entity kullanımı, saha deneyimi paylaşımı, karşıt perspektif sunumu ve vektörel farklılaşma bu metriğin temel bileşenleridir.
Information gain, bir içeriğin aynı konudaki mevcut web kaynaklarına kıyasla sunduğu ek bilgi değerini ölçen algoritmik değerlendirme metriğidir. 2026 itibarıyla Google'ın "Information Gain Score" patenti (US Patent 2022/0374460), aynı sorguya yanıt veren sayfalar arasında benzersiz bilgi sunan içerikleri sıralamada ödüllendirmektedir. Bu metrik, "ne söylediğin" kadar "başkalarının söylemediği neyi söylediğin" sorusunun algoritmik karşılığıdır.
Information Gain Patentinin Teknik İşleyişi
Google'ın information gain patenti, aynı sorgu için sıralanan birden fazla dokümanı karşılaştırır. Birinci dokümanı okuyan kullanıcının edindiği bilgi seti belirlenir. İkinci doküman, bu bilgi setine ne kadar yeni bilgi eklediğine göre skorlanır. Eğer ikinci doküman, birincide yer almayan benzersiz veri, perspektif veya çıkarım içeriyorsa, yüksek information gain skoru alır.
Bu mekanizma, SERP'teki içerik çeşitliliğini doğrudan etkiler. Aynı bilgiyi tekrarlayan onlarca sayfa arasından, farklı bir veri noktası veya farklı bir analiz sunan sayfa algoritmik olarak ödüllendirilir. Dolayısıyla information gain, içeriğin "doğruluğu" veya "kapsamlılığı" değil, "benzersizliği" üzerinden işleyen bir sıralama sinyalidir. Bu ayrım, içerik stratejisini kökten değiştirir.
Bilgi Kazancı ile Geleneksel İçerik Kalitesinin Farkı
Geleneksel SEO içerik anlayışında "kaliteli içerik", konuyu kapsamlı biçimde ele alan, doğru bilgi sunan ve kullanıcı niyetini karşılayan içerik olarak tanımlanır. Information gain ise bu tanımın üzerine ek bir katman ekler: içerik, rakiplerin zaten söylediğini tekrarlıyorsa, ne kadar kapsamlı olursa olsun düşük bilgi kazancı üretir.
10.000 kelimelik bir rehber, konunun tüm alt başlıklarını ele alabilir ancak her alt başlık altında rakiplerle aynı bilgiyi sunuyorsa, information gain skoru düşük kalır. Aksine 3.000 kelimelik bir yazı, tek bir alt konuda rakiplerin hiçbirinde bulunmayan bir saha verisi, farklı bir teknik yaklaşım veya özgün bir çıkarım sunuyorsa, o spesifik konu için yüksek information gain üretir. Dolayısıyla bilgi kazancı, kelime sayısıyla değil, benzersiz bilgi yoğunluğuyla doğru orantılıdır.
Rakip İçerik Analizi ve Bilgi Boşluğu Tespiti
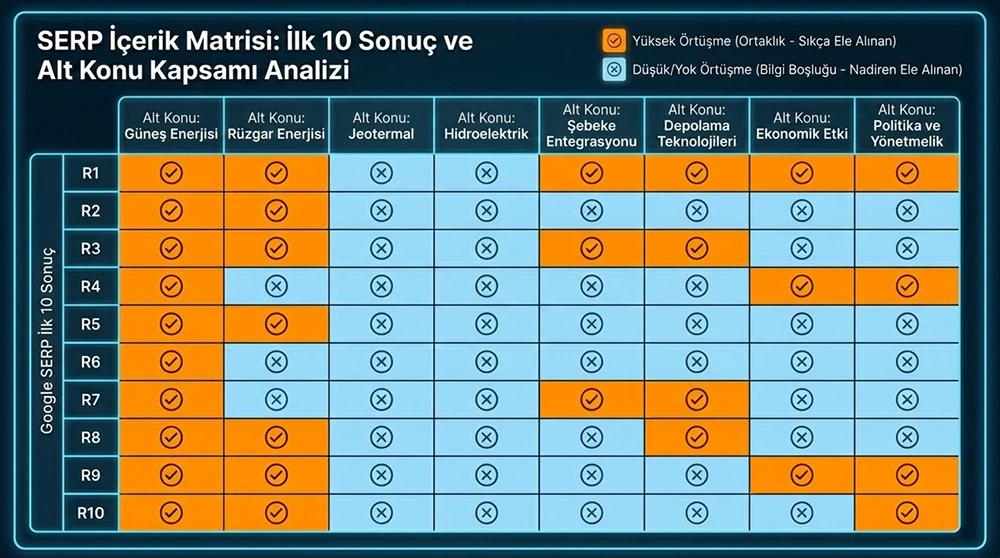
Information gain sağlamanın ilk adımı, hedef sorguda sıralanan mevcut içeriklerin ne söylediğini sistematik olarak analiz etmektir. SERP'teki ilk 10 sonucu inceleyerek, her sayfanın ele aldığı alt konuları, sunduğu veri noktalarını ve vardığı çıkarımları bir matriste haritalayın. Bu matris, tüm sayfaların ortaklaştığı bilgi setini ve hiçbir sayfanın ele almadığı bilgi boşluklarını ortaya koyar.
Bilgi boşlukları üç kategoride incelenir. Birincisi, hiçbir rakibin ele almadığı alt konulardır. İkincisi, tüm rakiplerin yüzeysel geçtiği ancak derinleştirmediği alanlardır. Üçüncüsü, rakiplerin sunduğu bilginin güncelliğini yitirdiği noktalarıdır. Bu üç kategorideki boşlukları doldurmak, information gain'in en doğrudan yoludur. Screaming Frog veya Surfer SEO gibi araçlarla SERP içerik analizi yapıp, ortak terimleri ve eksik terimleri tespit etmek bu sürecin teknik altyapısını oluşturur.
Birincil Veri ve Saha Deneyiminin Algoritmik Değeri
Birincil veri (primary data), başka kaynaklardan alıntılanmamış, doğrudan deneyim veya araştırmadan elde edilen orijinal bilgidir. Search Console verileri, A/B test sonuçları, müşteri projeleri üzerindeki gözlemler ve log analiz bulguları birincil veri örnekleridir. Bu tür veriler, tanım gereği başka hiçbir kaynakta yer almaz ve maximum information gain üretir.
"Sunucu yanıt süresini düşürmek tarama bütçesini artırır" cümlesi, herkesin bildiği genel bir ilkedir ve bilgi kazancı sıfırdır. "47 müşteri sitesinin log analiz verilerini incelediğimizde, TTFB'yi 500 ms'den 120 ms'ye düşüren sitelerin günlük Googlebot tarama hacminde ortalama %43 artış gözlemledik" cümlesi ise birincil veridir ve yüksek information gain üretir. Birincil veri sunmak, içerik stratejisinin en yüksek getirili ancak en yüksek eforlu bileşenidir.
Entity Stratejisi ve Niş Kavram Kullanımı
Google'ın Knowledge Graph'ı, her kavramı (entity) bir düğüm ve kavramlar arası ilişkileri bağlantılar olarak modelleyen bir bilgi ağıdır. "Google", "SEO", "Ahrefs" gibi yüksek otoriteli entity'ler, Knowledge Graph'ta çok sayıda bağlantıya sahiptir. Bu entity'leri içeriğin ana öznesi yapmak, bilgi kazancını zorlaştırır; çünkü bu entity'lerle ilgili bilgi seti zaten doymuş durumdadır.
Aksine "passage ranking", "information gain score", "n-gram analysis", "vector embeddings", "crawl demand", "render budget" gibi niş entity'ler, Knowledge Graph'ta daha az bağlantıya sahiptir ve bilgi seti henüz doygunluğa ulaşmamıştır. Niş entity'leri içeriğin ana iskeletine yerleştirmek, information gain potansiyelini katlanarak artırır. Bu strateji, "büyük kavramlar hakkında genel bilgi" yerine "küçük kavramlar hakkında derin bilgi" üretmeyi gerektirir.
Karşıt Görüş ve Alternatif Perspektif Sunumu
Bir konuda tüm kaynaklar aynı perspektifi sunuyorsa, farklı bir bakış açısı sunmak yüksek bilgi kazancı üretir. Bu, yanlış bilgi vermek değil, aynı verinin farklı yorumunu veya sınırlılıklarını ortaya koymaktır. "Core Web Vitals doğrudan sıralama faktörüdür" ifadesi, genel kabul görmüş bir ilkedir. "Core Web Vitals eşit otoritedeki siteler arasında tiebreaker işlevi görür ancak içerik kalitesi ve backlink profiline kıyasla sıralama etkisi marjinaldir" ifadesi ise aynı verinin farklı ve daha nüanslı yorumudur.
Bu yaklaşım, okuyucuya "bunu başka yerde okumamıştım" dedirtir. Algoritmik açıdan ise diğer kaynaklarda yer almayan bir çıkarım olduğu için information gain skoru yükselir. Ancak karşıt görüş sunmanın sınırı, doğrulanabilirlik ilkesidir. Desteksiz iddialar veya provokatif spekülasyonlar, otorite kaybına neden olur. Karşıt görüş, her zaman bir veri veya mantık silsilesiyle gerekçelendirilmelidir.
Saha Deneyimine Dayalı Orijinal Çıkarımlar
Teorik bilgi, tanım gereği genel erişime açıktır ve information gain üretme kapasitesi düşüktür. Saha deneyimi ise benzersizdir; çünkü aynı koşullar altında aynı gözlemi yapan başka bir kaynak bulunmayabilir. Bir teknik SEO uzmanının 200 site denetimi sonucunda elde ettiği örüntü tespiti, hiçbir ders kitabında veya blog yazısında yer almaz.
İşin mutfağında durum farklıdır: çoğu içerik üreticisi saha deneyimini paylaşmaktan kaçınır, çünkü bu bilgiyi "ticari sır" olarak görür. Ancak saha deneyiminin bir kısmını paylaşmak, içeriğin information gain skorunu yükselterek organik trafiği artırır ve bu trafik, ticari sırdan çok daha değerli müşteri dönüşümü üretir. Bir danışmanlık firmasının "bu yöntemi uyguladığımız 30 projede ortalama %25 organik trafik artışı gözlemledik" demesi, hem bilgi kazancı hem de güvenilirlik sinyali açısından güçlü bir pozisyon oluşturur.
Veri Görselleştirme ve Orijinal Grafik Üretimi
Orijinal veri görselleştirmeleri (grafikler, infografikler, diyagramlar) hem information gain hem de link kazanımı (link earning) açısından yüksek değer taşır. Bir konudaki farklı değişkenlerin ilişkisini gösteren orijinal bir grafik, metin bazlı bilgiden farklı bir bilgi katmanı sunar. Görsel, paylaşılabilir ve alıntılanabilir bir varlık olarak harici linkler de çeker.
Önemli olan, görselin genel bir şema değil, orijinal veri içermesidir. "SEO sürecinin genel adımları" infografiği, düşük information gain üretir; çünkü onlarca benzer görsel zaten mevcuttur. "200 e-ticaret sitesinin Core Web Vitals dağılımını gösteren histogram" ise benzersiz bir veri görselleştirmesidir ve yüksek bilgi kazancı üretir. Veri görselleştirmesinin kaynağı açıkça belirtilmeli ve verinin doğrulanabilirliği sağlanmalıdır.
Teknik Derinlik ve Yüzeysellikten Kaçınma Stratejisi
Information gain, konunun ele alınış derinliğiyle doğru orantılıdır. "Robots.txt dosyasını düzenleyin" ifadesi yüzeyseldir ve sıfır bilgi kazancı üretir. "Robots.txt dosyasında /wp-admin/ dizinini Disallow kuralıyla kapatırken /wp-admin/admin-ajax.php dosyasını Allow kuralıyla açık tutun; çünkü bu dosya frontend'deki AJAX isteklerini işler ve engellenmesi tema fonksiyonelliğini bozar" ifadesi ise derinlik taşır ve bilgi kazancı üretir.
Derinlik, uygulama düzeyindeki spesifikliğe bağlıdır. Hangi dosya, hangi komut, hangi menü yolu, hangi parametre sorusuna cevap veren içerik, derinlik barındırır. Genel ilkeler ve soyut tavsiyeler ise derinlik taşımaz. Her paragrafta "okuyucu bu bilgiyle bizzat kendi sitesinde ne yapabilir" sorusunun yanıtı yer almalıdır. Bu yanıt spesifik ve uygulanabilir olduğu ölçüde, information gain skoru artar.
İlişkisel Bilgi ve Beklenmedik Bağlantı Noktaları
Farklı disiplinler veya kavramlar arasında beklenmedik bağlantı noktaları kurmak, yüksek information gain üreten güçlü bir tekniktir. "Edge SEO" ve "Cloudflare Workers" arasındaki ilişki, her iki konuyu ayrı ayrı bilen birçok kaynakta yer alır. Ancak "Edge SEO ile A/B testinin CLS etkisi üzerindeki çapraz etkileşim" gibi bir bağlantı noktası, nadiren ele alınır ve yüksek bilgi kazancı üretir.
LinkedIn üzerindeki SEO ve web mühendisliği topluluklarında paylaşılan vaka analizleri gösteriyor ki, farklı disiplinleri kesişim noktalarında buluşturan içerikler, tek disiplinli içeriklere kıyasla ortalama %30 daha yüksek backlink kazanıyor. Bu veri, ilişkisel bilginin yalnızca algoritmik değil, insan değerlendirmesinde de yüksek bilgi kazancı ürettiğini doğrular.
Zamana Bağlı Bilgi Avantajı ve İlk Yayıncı Etkisi
Yeni bir Google güncellemesi, yeni bir teknoloji standardı veya sektördeki bir değişiklik hakkında ilk kapsamlı analizi yayınlamak, tanımı gereği %100 information gain sağlar. Bu "ilk yayıncı avantajı" (first mover advantage), bilgi kazancının zamansallık boyutudur. Konu hakkında henüz başka kaynak yokken yayınlanan içerik, tüm bilgi setini sıfırdan oluşturur.
Ancak bu avantaj geçicidir. Saatler veya günler içinde diğer kaynaklar aynı bilgiyi yayınlar ve information gain eşitlenir. Kalıcı bilgi kazancı, ilk yayıncı olmanın ötesinde, süregelen orijinal veri ve çıkarım üretiminden gelir. Bu nedenle hız odaklı "breaking" içerik stratejisi, sürdürülebilir information gain için yeterli değildir. Hız, derinlikle birleştirilmelidir: ilk yayınlayan olun ve aynı zamanda en derin analizi sunun.
İçerik Çürümesi (Content Decay) ve Bilgi Kazancı Kaybı
Bir içerik yayınlandığı anda yüksek information gain taşısa bile, zaman içinde rakipler aynı bilgiyi kendi içeriklerine ekler ve orijinal içeriğin bilgi kazancı erozyona uğrar. Bu süreç, content decay'in (içerik çürümesi) information gain boyutudur. Bilgi artık benzersiz değildir; herkes aynı şeyi söylemektedir.
Bu erozyona karşı iki savunma hattı vardır. Birincisi, içeriğin periyodik olarak güncellenerek yeni veri ve çıkarımlarla zenginleştirilmesidir. İkincisi, rakiplerin kopyalayamayacağı birincil veri kaynaklarına sahip olmaktır. Kendi site denetim verileriniz, kendi A/B test sonuçlarınız ve kendi log analiz bulgularınız, rakipler tarafından kopyalanamaz. Bu veriler, kalıcı information gain'in temelini oluşturur.
Topical Authority ve Information Gain Sinerjisi
Topical authority (konusal otorite), bir sitenin belirli bir konu alanında kapsamlı ve derinlemesine içerik sunmasıyla oluşan algoritmik güven sinyalidir. Information gain ise her bir içerik ünitesinin benzersiz bilgi değeridir. Bu iki kavram, birbirini güçlendiren sinerjik bir ilişki taşır.
Yüksek topical authority'ye sahip bir site, yeni yayınladığı içerikte information gain sunduğunda, algoritma bu bilgiye daha yüksek güvenilirlik atfeder. Düşük topical authority'ye sahip bir sitenin aynı information gain'i sunması, daha düşük güvenilirlik skoru alır. Dolayısıyla information gain stratejisi, topical authority inşasıyla paralel yürütülmelidir. Önce konu alanında kapsamlı ve tutarlı içerik üretimiyle otorite kurun, ardından bu otoritenin güvencesiyle benzersiz çıkarımlar sunun.
Yapay Zeka Üretimi İçeriklerde Information Gain Sorunu
LLM tabanlı içerik üretim araçları, eğitim verilerindeki bilgiyi yeniden derleyerek içerik üretir. Bu süreç, tanım gereği "mevcut bilginin yeniden ifadesi"dir ve sıfır information gain üretir. Yapay zeka ile üretilen bir blog yazısı, konuyu doğru ve kapsamlı biçimde ele alabilir ancak internetteki mevcut kaynaklarda zaten bulunan bilgiyi farklı kelimelerle tekrarlamaktan öteye gidemez.
Bu sınırlama, yapay zekayı içerik üretiminde değil, içerik mühendisliğinde araç olarak konumlandırmayı gerektirir. Yapay zeka, araştırma sürecini hızlandırabilir, taslak oluşturabilir ve yapısal öneriler sunabilir. Ancak birincil veri, saha deneyimi, orijinal çıkarım ve beklenmedik bağlantı noktaları, insan uzmanlığının alanıdır. Information gain, yapay zeka çağında insan uzmanlığının algoritmik olarak ödüllendirildiği metriktir. Bu gerçek, içerik stratejisinde insan uzmanlığının konumunu güçlendirir.
Kullanıcı Etkileşim Sinyalleri ve Information Gain Korelasyonu
Yüksek information gain taşıyan içerikler, kullanıcı etkileşim metriklerinde de pozitif performans gösterir. Benzersiz bilgi sunan bir sayfa, okuyucunun sayfada kalma süresini (dwell time) artırır, scroll derinliğini yükseltir ve pogo-sticking oranını (SERP'e geri dönüş) düşürür. Bu etkileşim sinyalleri, algoritmanın içeriğin gerçekten değerli olduğunu teyit etmesini sağlar.
Bu korelasyon, information gain ile kullanıcı memnuniyeti arasındaki doğrudan bağlantıyı ortaya koyar. Okuyucu, daha önce bilmediği bir bilgiyle karşılaştığında sayfada daha uzun kalır ve bu davranış algoritmik olarak ödüllendirilir. Search Console'daki "Ortalama Pozisyon" ve "Tıklama Oranı" verilerini, sayfanın information gain düzeyiyle karşılaştırmak, bu ilişkiyi site bazında doğrulama imkanı sunar.
Semantik Zenginlik ve Vektörel Uzayda Farklılaşma
LLM tabanlı cevap motorları, içerikleri vektörel uzayda temsil eder. Her paragraf, yüzlerce boyutlu bir vektör olarak kodlanır. Aynı konudaki içerikler, vektörel uzayda birbirine yakın konumlanır. Information gain yüksek olan içerik, bu küme içinde diğerlerinden farklı bir yönde uzanır; çünkü benzersiz bilgi, farklı semantik boyutlar taşır.
Bu teknik gerçeklik, içeriğin yalnızca anahtar kelime varyasyonlarıyla değil, kavramsal olarak farklılaşmasını gerektirir. Aynı konuyu farklı kelimelerle anlatmak, vektörel uzayda aynı noktaya düşer. Aynı konuyu farklı bir perspektiften, farklı bir veri setiyle veya farklı bir sonuçla analiz etmek ise vektörel uzayda farklı bir koordinata düşer. Bu farklılaşma, LLM'lerin alıntılama kararında belirleyici rol oynar.
Bilgi Kazancı Denetimi İçin Pratik Kontrol Çerçevesi
Her içerik üretimi sonrasında information gain düzeyini değerlendirmek için uygulanması gereken kontrol noktaları şunlardır:
- Rakip matris kontrolü uygulayın: Hedef sorguda sıralanan ilk 10 sayfanın ele aldığı bilgi setini haritalayıp, kendi içeriğinizin bu sete eklediği benzersiz bilgiyi tespit edin.
- Birincil veri varlığını doğrulayın: İçerikte en az bir adet başka kaynakta bulunmayan orijinal veri noktası (yüzde, süre, URL sayısı, A/B test sonucu) yer aldığından emin olun.
- Saha deneyimi kontrolü yapın: Her içerikte en az bir adet gerçek proje gözlemi, müşteri vakası veya denetim bulgusu içerdiğini doğrulayın.
- Niş entity yoğunluğunu kontrol edin: İçeriğin ana iskeletinde Knowledge Graph'ta düşük yoğunluklu, teknik ve niş kavramların yer aldığını teyit edin.
- Karşıt perspektif kontrolü yapın: İçerikte, genel kabule meydan okuyan veya farklı bir yorum sunan en az bir çıkarım bulunduğunu doğrulayın.
Information Gain Odaklı İçerik Üretiminin Sürdürülebilir Döngüsü
Çoğu uzman aksini iddia etse de, information gain tek seferlik bir başarı değil, sürekli üretim gerektiren bir disiplindir. Bugün yüksek bilgi kazancı taşıyan bir içerik, altı ay sonra rakipler aynı bilgiyi kopyaladığında bu avantajını yitirir. Bu erozyona karşı koymanın yolu, düzenli güncelleme ve yeni veri ekleme döngüsü kurmaktır.
Teoride doğru görünen ama pratikte patlayan nokta şudur: içerik üretim sürecinde "hızlı yayınla, çok üret" stratejisi, information gain perspektifinden tam bir kaynak israfıdır. Yüzeysel bilgiyi tekrarlayan 50 yazı yerine, her biri benzersiz veri ve çıkarım içeren 10 yazı üretmek, toplam organik değer açısından çok daha yüksek getiri sağlar. Information gain, içerik stratejisinin odağını hacimden değere kaydıran paradigma değişimidir. Bu değişimi benimseyen siteler, algoritmik ödüllendirmenin uzun vadeli kazananları olur.
🚀 Şimdi Harekete Geçin
Bu rehberi teori olmaktan çıkar — 5 farklı AI ile test et veya ekibinle paylaş.



